The following are our communication library primitives which are useful for routing most data movements. Our algorithms will be described as shared-memory programs that make use of these primitives and do not make any assumptions of how these primitives are actually implemented. In our analysis, we use the BDM model and the results of [26] and [27].
The basic data transport is a read or write operation. The remote read and write typically have both blocking and non-blocking versions. Also, when reading or writing more than one element, bulk data transports are provided with corresponding bulk_read and bulk_write primitives. The first hierarchy of collective communication primitives are similar to those for the IBM POWERparallel machines [8], the Cray MPP systems [15], standard message passing [29], and communication libraries for shared memory languages on distributed memory machines, such as Split-C [16], and include the following: bcast, reduce, combine, scatter, gather, concat, transpose, and prefix. A higher level primitive redist is described later for dynamic data redistribution.
Note that shared arrays are held in distributed memory across a set of
processors. A typical array, 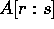 contains s-r+1 elements, each
assigned to a location in a unique processor. Collective
communications are defined on process groups, namely, the subset
of processors which hold elements from array A. For example, the
process group is defined to have p = s-r+1 processors, logically and
consecutively ranked from 0 to p-1. In general, nothing is known
about the physical layout of A, which is assumed to be arbitrary,
i.e.
contains s-r+1 elements, each
assigned to a location in a unique processor. Collective
communications are defined on process groups, namely, the subset
of processors which hold elements from array A. For example, the
process group is defined to have p = s-r+1 processors, logically and
consecutively ranked from 0 to p-1. In general, nothing is known
about the physical layout of A, which is assumed to be arbitrary,
i.e.  and
and  might reside on
might reside on  and
and  , for any
, for any  . For ease of describing the primitives below, we normalize
. For ease of describing the primitives below, we normalize
 by relabeling it as
by relabeling it as 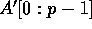 , where p is defined
as s-r+1. Note that this is just a change of variable to simplify
the discussion, and not a physical remapping of the data.
, where p is defined
as s-r+1. Note that this is just a change of variable to simplify
the discussion, and not a physical remapping of the data.