We use a simple model to analyze the performance of our parallel algorithms. Each of our hardware platforms can be viewed as a collection of powerful processors connected by a communication network that can be modeled as a complete graph on which communication is subject to the restrictions imposed by the latency and the bandwidth properties of the network. We view a parallel algorithm as a sequence of local computations interleaved with communication steps, and we allow computation and communication to overlap. We account for communication costs as follows.
The transfer of a block consisting of m contiguous words, assuming
no congestion, takes O time, where
time, where  is an
upper bound on the latency of the network and
is an
upper bound on the latency of the network and 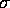 is the time per
word at which a processor can inject or receive data from the network.
The cost of each of the communication primitives will be modeled by
O
is the time per
word at which a processor can inject or receive data from the network.
The cost of each of the communication primitives will be modeled by
O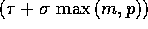 , where m is the maximum amount of data
transmitted or received by a processor. Such cost (which is an
overestimate) can be justified by using our earlier work
[26,27,6,7]. Using this cost model, we can evaluate the
communication time
, where m is the maximum amount of data
transmitted or received by a processor. Such cost (which is an
overestimate) can be justified by using our earlier work
[26,27,6,7]. Using this cost model, we can evaluate the
communication time 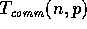 of an algorithm as a function of the input
size n, the number of processors p , and the parameters
of an algorithm as a function of the input
size n, the number of processors p , and the parameters  and
and
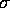 . The coefficient of
. The coefficient of  gives the total number of times
collective communication primitives are used, and the coefficient of
gives the total number of times
collective communication primitives are used, and the coefficient of
 gives the maximum total amount of data exchanged between a
processor and the remaining processors.
gives the maximum total amount of data exchanged between a
processor and the remaining processors.
This communication model is close to a number of similar models (e.g. [18,44,2]) that have recently appeared in the literature and seems to be well-suited for designing parallel algorithms on current high performance platforms.
We define the computation time 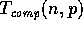 as the maximum time it takes a
processor to perform all the local computation steps. In general, the
overall performance
as the maximum time it takes a
processor to perform all the local computation steps. In general, the
overall performance  involves a tradeoff between
involves a tradeoff between
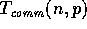 and
and  . Our aim is to develop parallel algorithms that
achieve
. Our aim is to develop parallel algorithms that
achieve  such that
such that 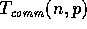 is minimum,
where
is minimum,
where  is the complexity of the best sequential algorithm. Such
optimization has worked very well for the problems we have looked at,
but other optimization criteria are possible. The important point to
notice is that, in addition to scalability, our optimization criterion
requires that the parallel algorithm be an efficient sequential
algorithm (i.e., the total number of operations of the parallel
algorithm is of the same order as
is the complexity of the best sequential algorithm. Such
optimization has worked very well for the problems we have looked at,
but other optimization criteria are possible. The important point to
notice is that, in addition to scalability, our optimization criterion
requires that the parallel algorithm be an efficient sequential
algorithm (i.e., the total number of operations of the parallel
algorithm is of the same order as  ).
).