A fundamental challenge for parallel computing is to obtain high-level, architecture independent, algorithms which efficiently execute on general-purpose parallel machines. This problem has become more tractable with the advent of message passing standards such as MPI [33], which seek to guarantee the availability of efficient implementations of certain basic collective communication routines. However, these proposed primitives are all regular in nature and exclude certain pervasive non-uniform communication tasks such as the h-relation personalized communication. In this problem, each processor has possibly different amounts of data to share with some subset of the other processors, such that each processor is the origin or destination of at most h messages. Clearly, such a task is endemic in parallel processing (e.g. [22,44,36]), and several authors have identified its efficient implementation as a prerequisite to efficient general purpose computing ([44]). In particular, in his ``bridging model'' for parallel computation, Valiant has identified the h-relation personalized communication as the basis for organizing communication between two consecutive major computation steps.
Previous parallel algorithms for personalized communication (typically for a hypercube, e.g. [28,40,37,12,13,10,1], a mesh, e.g. [24,39,29,14,25], or other circuit switched network machines, e.g. [34,19,32,38]) tend to be network or machine dependent, and thus not efficient when ported to current parallel machines. In this paper, we introduce a novel deterministic algorithm that is shown to be both efficient and scalable across a number of different platforms. In addition, the performance of our algorithm is invariant over the set of possible input distributions, unlike most of the published implementations.
As an application of this primitive, we consider the problem of
sorting a set of n integers spread across a p-processor
distributed memory machine, where 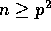 . Fast integer sorting
is crucial for solving problems in many domains, and, as such, is used
as a kernel in several parallel benchmarks such as NAS
. Fast integer sorting
is crucial for solving problems in many domains, and, as such, is used
as a kernel in several parallel benchmarks such as NAS![]() [8] and SPLASH [46]. Because of the extensive and
irregular communication requirements, previous parallel algorithms for
sorting (a hypercube, e.g. [11,1], or a mesh, e.g.
[21,31]) tend to be network or machine dependent, and
therefore not efficient across current parallel machines. In this
paper, we present an algorithm for integer sorting which couples the
well known parallel radix sort algorithm together with our algorithm
for personalized communication. We show that this sorting algorithm is
both efficient and scalable across a number of different platforms.
[8] and SPLASH [46]. Because of the extensive and
irregular communication requirements, previous parallel algorithms for
sorting (a hypercube, e.g. [11,1], or a mesh, e.g.
[21,31]) tend to be network or machine dependent, and
therefore not efficient across current parallel machines. In this
paper, we present an algorithm for integer sorting which couples the
well known parallel radix sort algorithm together with our algorithm
for personalized communication. We show that this sorting algorithm is
both efficient and scalable across a number of different platforms.
Our algorithms are implemented in Split-C [17], an extension of C for distributed memory machines. The algorithms make use of MPI-like communication primitives but do not make any assumptions as to how these primitives are actually implemented. The basic data transport is a read or write operation. The remote read and write typically have both blocking and non-blocking versions. Also, when reading or writing more than a single element, bulk data transports are provided with corresponding bulk_read and bulk_write primitives. Our collective communication primitives, described in detail in [7], are similar to those of MPI [33], the IBM POWERparallel [9], and the Cray MPP systems [16] and, for example, include the following: transpose, bcast, gather, and scatter. Brief descriptions of these are as follows. The transpose primitive is an all-to-all personalized communication in which each processor has to send a unique block of data to every processor, and all the blocks are of the same size. The bcast primitive is called to broadcast a block of data from a single source to all the remaining processors. The primitives gather and scatter are companion primitives whereby scatter divides a single array residing on a processor into equal-sized blocks which are then distributed to the remaining processors, and gather coalesces these blocks residing on the different processors into a single array on one processor. See [7,6,5] for algorithmic details, performance analyses, and empirical results for these communication primitives.
The organization of this paper is as follows. Section 2 presents our computation model for analyzing parallel algorithms. The Communication Library Primitive operations which are fundamental to the design of high-level algorithms are given in [7]. Section 3 introduces a practical algorithm for realizing h-relation personalized communication using these primitives. A parallel radix sort algorithm using the routing of h-relations is presented in Section 4. Finally, we describe our data sets and the experimental performance of our integer sorting algorithm in Section 5.