Graphics and Visualization
The CPU-GPU coupled cluster and LCD display wall are excellent resources for visualization and graphics applications. This powerful computational infrastructure enables real time visual exploration of large scale volumetric data sets in high resolution. Furthermore, it is an ideal testbench for research in Computer Graphics, and has already been utilized in projects related to parallel rendering and an has been utilized for projects in data visualization as well as aspects of computer graphics including rendering from compressed data and parallel rendering.Visual Analysis of Large-Scale Time-Varying Data
We have worked on the problem of isosurface extraction and rendering for large scale time varying data. Such datasets have been appearing at an increasing rate especially from physics-based simulations, and can range in size from hundreds of gigabytes to tens of terabytes. As an example, consider the fundamental mixing process of the Richtmyer-Meshkov instability in inertial confinement fusion and supernovae from the ASCI team at the Lawrence Livermore National Labs. This dataset represents a simulation in which two gases, initially separated by a membrane, are pushed against a wire mesh. These are then perturbed with a superposition of long wavelength and short wavelength disturbances and a strong shock wave. This simulation took 9 days on 960 CPUs and produced about 2.1 terabytes of simulation data. The data shows the characteristic development of bubbles and spikes and their subsequent merger and break-up over 270 time steps. Each time step is simulated over a 2048 x 2048 x 1920 grid, has isosurfaces exceeding 500 million triangles with an average depth complexity of 50. We have explored interactive rendering and visualization of such datasets. The highlights of our work are:

Richtmyer-Meshkov instability dataset
We have developed a new simple indexing scheme for parallel out-of-core processing of large scale datasets, which enables the identification of the active cells extremely quickly, using more compact indexing structure and more effective bulk data movement than previous schemes [Wang et al. 06, Wang et al. 07]
A new data layout scheme for large scale volumetric data sets, which enables very fast slicing along any dimension. This scheme is provably faster than any of the previous schemes and can be applied to any high dimensional data [Kim and JaJa 07].
We have introduced the Persistent Octree indexing structure that can be used to accelerate isosurface extraction and spatial filtering for volumetric data. The new scheme can be used to perform view-dependent isosurfacing and 4-D isocontour slicing much faster than was possible before [Shi and JaJa 06].
We have developed a new method for the interactive rendering of isosurfaces using ray tracing on multi-core processors and show that this method is both efficient and scalable. We achieve interactive isosurface rendering on a screen with 1024 x 1024 resolution for all the data sets tested up to the maximum size that can fit in the main memory of our platform [Wang and JaJa 07].
Parallel Rendering
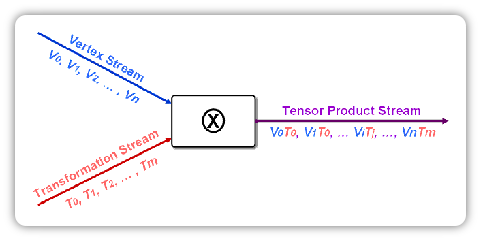
Vertex Stream Data Flow
Recent trends in parallel computer architecture strongly suggest the need to improve the arithmetic intensity (the compute to bandwidth ratio) for greater performance in time-critical applications, such as interactive 3D graphics. We have explored the interactions between multiple data streams to improve arithmetic intensity and address the input geometry bandwidth bottleneck for interactive 3D visualization applications [Kim et al. 06]. We have shown how to factor point datasets into a set of source vertices and transformation streams by identifying the most common translations amongst vertices. We accomplish this by identifying peaks in the cross-power spectrum of the dataset in the Fourier domain. Our scheme can achieve a factor of 2X to 5X reduction of geometry bandwidth requirements.
We also plan to design and evaluate hybrid and reconfigurable graphics rendering pipelines for parallel and distributed graphics on the CPU-GPU cluster and tiled-display. The graphics pipeline can be divided into two stages -- geometry processing (transformations, clipping, and lighting) and raster processing (scan-conversion, visibility, shading, texture mapping, and compositing). One of the most interesting ways of looking at parallel graphics is to consider the stage at which the depth sorting of display primitives is carried out. While almost all parallel rendering approaches have relied on one sorting scheme, we plan to explore reconfigurable and hybrid sorting schemes that can dynamically change the type of sorting algorithms based on the available mix of primitives, pixels, computing, and bandwidth.
Rendering from Compressed Data

Rendering of the Stanford Lucy Model from a Compressed Statistical Representation
We have also investigated schemes that allow direct rendering from compressed data for cluster-based hybrid CPU-GPU rendering. Specifically, we have developed a multiresolution and progressive implicit representation of scalar volumetric data using anisotropic Gaussian radial basis functions (RBFs) defined over an octree [Juba and Varshney 07]. Our representation lends itself well to progressive level-of-detail representations. Our RBF encoding algorithm based on a Maximum Likelihood Estimation (MLE) calculation is non-iterative, scales in a O(nlogn) manner, and operates in a memory-friendly manner on very large datasets by processing small blocks at a time. We have also developed a GPU-based ray-casting algorithm for direct rendering from implicit volumes. Our GPU-based implicit volume rendering algorithm is accelerated by early-ray termination and empty-space skipping for implicit volumes and can render 16-million-RBF-encoded volumes at 1 to 3 frames/second. The octree hierarchy enables the GPU-based ray-casting algorithm to efficiently traverse using location codes and is also suitable for view-dependent level-of-detail-based rendering.
In the future, we plan to investigate other strategies that will permit direct rendering from compressed data representing geometry, connectivity, illumination, and shading (including textures) information in an integrated framework.