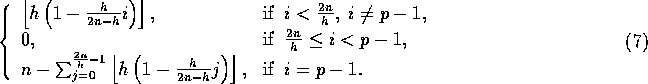Figure 1: Final distribution of the keys corresponding to our input data sets
We examine the performance of our h-relation algorithm on various
configurations of the TMC CM-5, IBM SP-2, Meiko CS-2, and Cray T3D,
using four values of h: 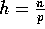 ,
, 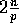 ,
,
 , and
, and 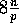 . The data sets used in these
experiments are defined as follows. Our input of size n is initially
distributed cyclically across the p processors such that each
processor
. The data sets used in these
experiments are defined as follows. Our input of size n is initially
distributed cyclically across the p processors such that each
processor  initially holds
initially holds 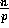 keys, for
keys, for 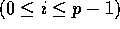 . For
. For 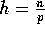 the input consists of
the input consists of 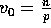 keys labelled for
keys labelled for 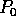 , followed by
, followed by 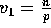 keys labelled for
keys labelled for  , and so forth, (with
, and so forth, (with  keys
labelled for
keys
labelled for 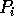 ), with the last
), with the last 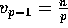 keys
labelled for
keys
labelled for  . Note that this results in the same data
movement as the transpose primitive
. Note that this results in the same data
movement as the transpose primitive![]() . For
. For  , instead
of an equal number of elements destined for each processor, the
function
, instead
of an equal number of elements destined for each processor, the
function 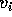 , for (
, for (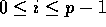 ), is characterized by
), is characterized by
The result of this data movement, shown in Figure 1,
is that processor 0 receives the largest imbalance of elements, i.e.
h, while other processors receive varying block sizes ranging from
0 to at most h. For 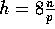 , approximately
, approximately
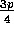 processors receive no elements, and hence this
represents an extremely unbalanced case. Note that in these tests,
each element consists of two integer
processors receive no elements, and hence this
represents an extremely unbalanced case. Note that in these tests,
each element consists of two integer![]() fields, data and dest, although only the
destination field dest is used to route each element.
fields, data and dest, although only the
destination field dest is used to route each element.

Figure 2: Performance of personalized communication (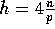 ) with respect to machine and problem size
) with respect to machine and problem size
As shown in Figure 2, the time to route an
h-relation personalized communication for a given input size on a
varying number of processors (p) scales inversely with p whenever
n is large compared with p. For small inputs compared with the
machine size, however, the communication time is dominated by
O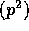 as shown in the case of the 128-processor Cray T3D with
n = 256K. The routing time for a fixed problem and machine size
varies directly with the parameter h (see Figure 6 in
Appendix A). These empirical results from a variety of
parallel machines are consistent with the analysis given in
Eq. (8). We have used vendor-supplied libraries
for collective communication primitives on the IBM SP-2
implementation. The other machines used in this experiment do not have
vendor-supported collective communication libraries, and hence we used
our generic communication primitives as described in
[7,6,5].
as shown in the case of the 128-processor Cray T3D with
n = 256K. The routing time for a fixed problem and machine size
varies directly with the parameter h (see Figure 6 in
Appendix A). These empirical results from a variety of
parallel machines are consistent with the analysis given in
Eq. (8). We have used vendor-supplied libraries
for collective communication primitives on the IBM SP-2
implementation. The other machines used in this experiment do not have
vendor-supported collective communication libraries, and hence we used
our generic communication primitives as described in
[7,6,5].