Given an 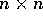 image with k grey levels on a p processor
machine (
image with k grey levels on a p processor
machine (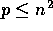 ), we wish to develop efficient and portable
parallel algorithms to perform various useful image processing
computations. Efficiency is a performance measure used to evaluate
parallel algorithms. This measure provides an indication of the
effective utilization of the p processors relative to the given
parallel algorithm. For example, an algorithm with an efficiency near
one runs approximately p times faster on p processors than the
same algorithm on a single processor. Portability refers to code that
is written independently of low-level primitives reflecting machine
architecture or size. Our goal is to develop portable algorithms that
are scalable in terms of both image size and number of processors,
when run on distributed memory multiprocessors.
), we wish to develop efficient and portable
parallel algorithms to perform various useful image processing
computations. Efficiency is a performance measure used to evaluate
parallel algorithms. This measure provides an indication of the
effective utilization of the p processors relative to the given
parallel algorithm. For example, an algorithm with an efficiency near
one runs approximately p times faster on p processors than the
same algorithm on a single processor. Portability refers to code that
is written independently of low-level primitives reflecting machine
architecture or size. Our goal is to develop portable algorithms that
are scalable in terms of both image size and number of processors,
when run on distributed memory multiprocessors.
Image segmentation algorithms cluster pixels into homogeneous regions, which, for example, can be classified into categories with higher accuracy than could be obtained by classifying the individual pixels. Region growing is a class of techniques used in image segmentation algorithms in which, typically, regions are constructed by an agglomeration process that adds (merges) pixels to regions when those pixels are both adjacent to the regions and similar in property (most simply intensity) (e.g. [10], [13], [21], [41], [44]). Each pixel in the image receives a label from the region growing process; pixels will have the same label if and only if they belong to the same region. Our algorithm makes use of an efficient and fast parallel connected components algorithm which uses a novel approach for merging. For a detailed theoretical and experimental analysis of this algorithm, please refer to [4].
In real images, natural regions have significant variability in grey level. Noise, introduced from the scanning of the real scene into the digital domain, will cause single pixels outliers. Also, lighting changes can cause a gradient of grey levels in pixels across the same region. Because of these and other similar effects, we preprocess the image with a stable filter, the Symmetric Neighborhood Filter (SNF) [22], that smooths out the interior pixels of a region to a near-homogeneous level. Also, due to relative motion of the camera and the scene, as well as aperture effects, edges or regions are usually blurred so that the transition in grey levels between regions is not a perfect step over a single pixel, but ramps from one region to the other over several pixels. Our filter is, additionally, an edge-preserving filter which can detect blurred transitions such as these and sharpens them while preserving the true border location as best as possible. Most preprocessing filters will smooth the interior of regions at the cost of degrading the edges, or conversely, detect edges while introducing intrinsic error on previously homogeneous regions. However, the SNF is an edge-preserving smoothing filter which performs well for both edge-sharpening and region smoothing. It is an iterative filter which also can be tuned to retain thin image structures corresponding, e.g., to rivers, roads, etc. A variety of SNF operators have been studied, and we chose a single parameter version which has been shown to perform well on remote sensing applications.
The majority of previous parallel implementations of the SNF filter
are architecture- or machine-specific and do not port well to other
platforms (e.g. [19], [30], [31],
[32], [37]). For example, [38] gives an
implementation of a 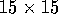 SNF filter on the CMU Warp, a
10-processor linear systolic array, which takes 4.76 seconds on a
SNF filter on the CMU Warp, a
10-processor linear systolic array, which takes 4.76 seconds on a
 image. We present our SNF filter execution timings in
Figure 10. In comparison, on a 32-processor TMC CM-5,
we take less than 165 milliseconds per iteration operating on an image
of equivalent size.
image. We present our SNF filter execution timings in
Figure 10. In comparison, on a 32-processor TMC CM-5,
we take less than 165 milliseconds per iteration operating on an image
of equivalent size.
After the image is enhanced by the SNF, we use a variant of the
connected components algorithm for grey level images, called  -Connected Components ,
to combine similar pixels into homogeneously labeled regions producing
the final image segmentation. As with the SNF implementations, most
previous parallel algorithms for segmentation do not port well to
other platforms (e.g. [17], [28], [29],
[36], [41], [42]).
-Connected Components ,
to combine similar pixels into homogeneously labeled regions producing
the final image segmentation. As with the SNF implementations, most
previous parallel algorithms for segmentation do not port well to
other platforms (e.g. [17], [28], [29],
[36], [41], [42]).
Section 2 addresses the algorithmic model and various
primitive operations we use to analyze the algorithms.
Section 3 discusses the test images, as well as the data
layout on the parallel machines. Our segmentation process overview
which includes discussion of SNF and 1-Nearest Neighbor filters, and the 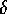 -Connected Components
algorithm, is given in Section 4. Finally,
Sections 5 and 6 describe the parallel
implementations of the Symmetric Neighborhood Filter algorithm and
-Connected Components
algorithm, is given in Section 4. Finally,
Sections 5 and 6 describe the parallel
implementations of the Symmetric Neighborhood Filter algorithm and
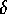 -Connected Components , respectively, and present algorithmic analyses and empirical
results.
-Connected Components , respectively, and present algorithmic analyses and empirical
results.
The experimental data obtained reflect the execution times from implementations on the TMC CM-5, IBM SP-1 and SP-2, Meiko CS-2, Cray Research T3D, and the Intel Paragon, with the number of parallel processing nodes ranging from 16 to 128 for each machine when possible. The shared memory model algorithms are written in SPLIT-C [14], a shared memory programming model language which follows the SPMD (single program multiple data) model on these parallel machines, and the source code is available for distribution to interested parties.