% ./tokenize1.pl < example.txtYou can ignore the top and bottom of the Perl source; all that matters is the regular expression in the middle:
[A-Za-z]+ # words | [0-9]+ # numbers | 's | -- # some special symbols | [^ ] # individual symbols
Note that here whitespace and comments are allowed, and ignored, inside the regular expression (except inside square brackets, and except when escaped by a backslash).
- Run the tokenizer on /afs/glue.umd.edu/class/fall2006/ling/723/0101/public/hw3/fireswamp.txt.
- Extend the tokenizer to handle acronyms like R.O.U.S. and the like. It should be able to handle any acronym, not just a few. Provide your program listing and show that it works on fireswamp.txt. Show that it works on other acronyms by running on the following sentence:
- "Not Spew," said Hermione impatiently. "It's S.P.E.W. Stands for the Society for the Promotion of Elfish Welfare."
- Identify another problem in fireswamp.txt and fix it. Provide your program listing and the output on fireswamp.txt.
- Change your graph representation to allow arc labels. Encode the following NFA:
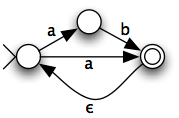
- Change the "push" step of the algorithm to push (state, position) pairs instead of just nodes (see J&M book, p. 44). Provide your program listing.
- Demonstrate that your algorithm works correctly using the following example strings and a few others:
- aaa
- bbb
- aab
Language models
- Create a bigram language model out of the Princess Bride script:
% ./make-lm.py -n 2 /afs/glue.umd.edu/class/fall2006/ling/723/0101/public/texts/princess.txt -o princess.lm
Have a look at the language model file. It should look like:sword. </s> 1.000000 memory. </s> 1.000000 at seeing 0.009709 at all 0.019417 at least, 0.009709 at her. 0.009709 at her, 0.019417 at hand, 0.009709 at last, 0.019417 at Humperdinck. 0.009709
Each line has an n-gram, and a probability: for example, the first line gives P(</s>|sword.). Notice that we have not done any tokenization -- you are welcome to try it with a tokenizer, but for consistency's sake we will all try untokenized text first.
- Use the probabilities in the language model file to calculate the probability of the string
I'm not left-handed.
Use grep to find the n-grams in the language model file, and of course you may use a calculator to multiply the probabilities together. Don't forget the start and stop symbols. Show the individual n-gram probabilities you used. Check your work against the computer's:% ./lm-score.py -m princess.lm I'm not left-handed. [Press control-D; you may have to press it twice] I'm not left-handed. => exp(-n.nnnnn)
The computer gives the answer as a logarithm (base 10) because in practice these probabilities can get very small.
- Give the random generator a try:
% ./lm-generate.py -m princess.lm -r 10
The -r 10 specifies the number of random sentences to generate. - Now for the interesting part: create some more language models on the same text, using different values of n (use the -n option). Try at least n=1 and n=3 or 4. For these new language models, looking up the probability of the string again -- what happens? Generating some random sentences -- does the quality go up or down? Explain.