For each experiment, the input is evenly distributed amongst the
processors. The output consists of the elements in non-descending order
arranged amongst the processors so that the elements at each processor
are in sorted order and no element at processor ![]() is
greater than any element at processor
is
greater than any element at processor ![]() , for all i < j.
, for all i < j.
Two variations were allowed in our experiments. First, radix sort was used to sequentially sort integers, whereas merge sort was used to sort double precision floating point numbers (doubles). Second, different implementations of the communication primitives were allowed for each machine. Wherever possible, we tried to use the vendor supplied implementations. In fact, IBM does provide all of our communication primitives as part of its machine specific Collective Communication Library (CCL) [7] and MPI. As one might expect, they were faster than the high level SPLIT-C implementation.
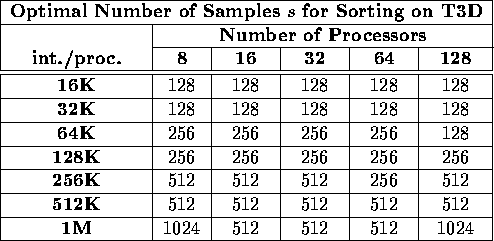
Table i: Optimal number of samples s for sorting the [WR] integer
benchmark on the Cray T3D, for a variety of processors and input sizes.
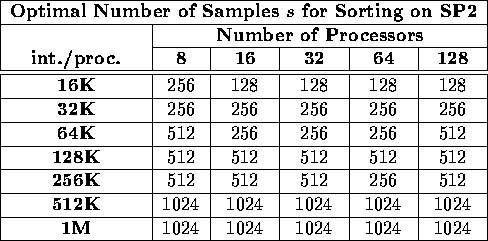
Table ii: Optimal number of samples s for sorting the [WR] integer
benchmark on the IBM SP-2-WN, for a variety of processors and input sizes.
Tables i and ii examine the
preliminary question
of the optimal number of samples s for sorting on the Cray T3D and the
IBM SP-2-WN. They show the value of s which achieved the best performance
on the Worst-Load Regular [WR] benchmark, as a function of both the
number of processors p and the number of keys per processor ![]() .
The results suggest that a good rule for choosing s is to set it to
.
The results suggest that a good rule for choosing s is to set it to
![]() ,
which is what we do for the remainder of this discussion.
To compare this choice for s with the theoretical expectation,
we recall that the complexity of Step (3) is
,
which is what we do for the remainder of this discussion.
To compare this choice for s with the theoretical expectation,
we recall that the complexity of Step (3) is ![]() ,
whereas the complexity of Step (9) is
,
whereas the complexity of Step (9) is ![]() . Hence, the first term is an increasing function of
s, whereas the second term is a decreasing function of s. It is easy
to verify that the expression for the sum of these two complexities
is minimized for s =
. Hence, the first term is an increasing function of
s, whereas the second term is a decreasing function of s. It is easy
to verify that the expression for the sum of these two complexities
is minimized for s = ![]() ,
and, hence, the theoretical expectation for the optimal value of s
agrees with what we observe experimentally.
,
and, hence, the theoretical expectation for the optimal value of s
agrees with what we observe experimentally.
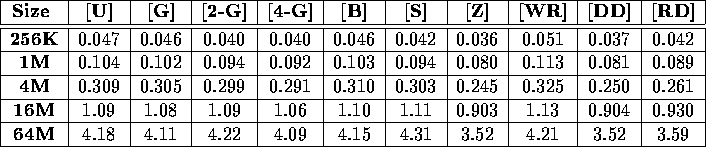
Table iii: Total execution time (in seconds) required to sort a variety of
integer benchmarks on a 64-node Cray T3D.
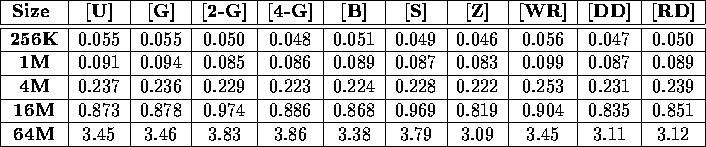
Table iv: Total execution time (in seconds) required to sort a variety
of integer benchmarks on a 64-node IBM SP-2-WN.
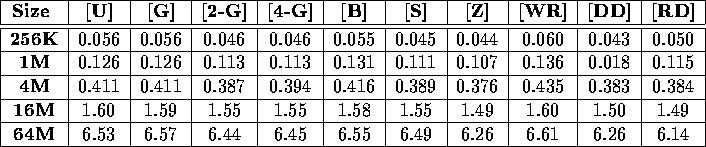
Table v: Total execution time (in seconds) required to sort
a variety of double benchmarks on a 64-node Cray T3D.
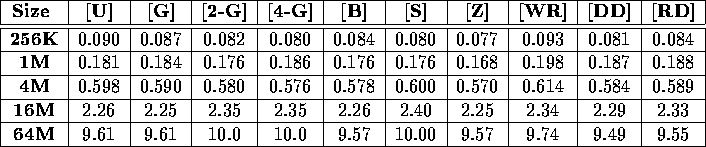
Table vi: Total execution time (in seconds) required to sort a variety
of double benchmarks on a 64-node IBM SP-2-WN.
Tables iii, iv, v, and vi display the performance of our sample sort as a function of input distribution for a variety of input sizes. In each case, the performance is essentially independent of the input distribution. These figures present results obtained on a 64 node Cray T3D and a 64 node IBM SP-2; results obtained from other platforms validate this claim as well. Because of this independence, the remainder of this section will only discuss the performance of our sample sort on the Worst-Load Regular benchmark [WR].
The results in Tables vii and viii together with
their graphs in Figure 1 examine the scalability of our sample
sort as a function of machine size. Results are shown for the T3D, the
SP-2-WN, and the CM-5. Bearing in mind that these graphs
are log-log plots, they show that, for a given input size n, the
execution time scales inversely with the number of processors
p for ![]() . While this is certainly the expectation of our analytical model
for doubles, it might at first appear to exceed our prediction of an
. While this is certainly the expectation of our analytical model
for doubles, it might at first appear to exceed our prediction of an
![]() computational complexity for integers.
However, the appearance of an inverse relationship is still quite
reasonable when we note that, for values of p between 8 and 64,
computational complexity for integers.
However, the appearance of an inverse relationship is still quite
reasonable when we note that, for values of p between 8 and 64,
![]() varies by only a factor of two.
Moreover, this
varies by only a factor of two.
Moreover, this ![]() complexity
is entirely due to the merging in Step (9), and in practice,
Step (9) never accounts for more than
complexity
is entirely due to the merging in Step (9), and in practice,
Step (9) never accounts for more than
![]() of the observed execution time. Note that the complexity
of Step (9) could be reduced to
of the observed execution time. Note that the complexity
of Step (9) could be reduced to ![]() for integers
using radix sort, but the resulting execution time would, in most cases,
be slower.
for integers
using radix sort, but the resulting execution time would, in most cases,
be slower.
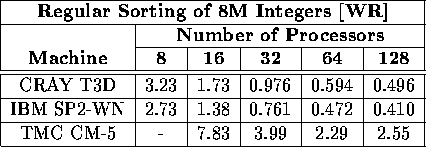
Table vii: Total execution time (in seconds) required to sort 8M integers
on a variety of machines and processors using the [WR] benchmark.
A hyphen indicates that particular platform was unavailable to us.
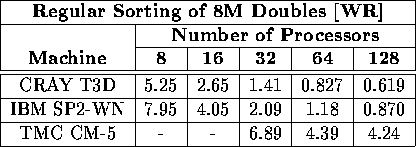
Table viii: Total execution time (in seconds) required to sort 8M doubles
on a variety of machines and processors using the [WR] benchmark.
A hyphen indicates that particular platform was unavailable to us.
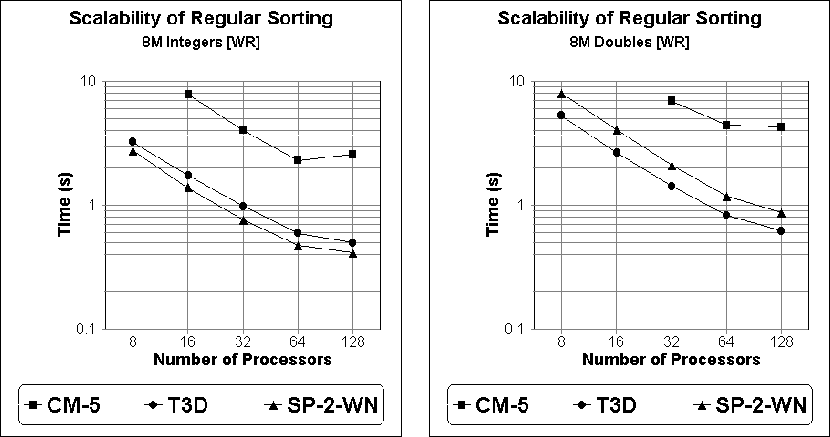
Figure 1: Scalability of sorting integers and doubles with respect
to machine size.
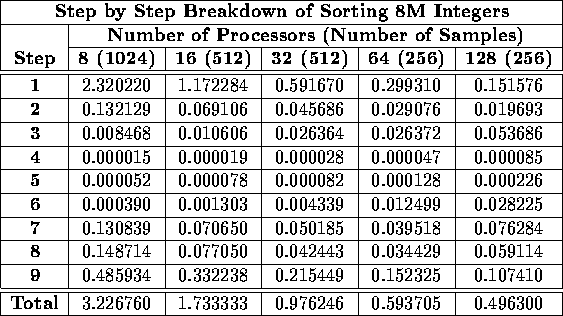
Table ix: Time required (in seconds) for each step of sorting 8M integers on the
Cray T3D using the [WR] benchmark.
However, the results in Tables vii and viii together with
their graphs in Figure 1 also show that for p greater than 64, the inverse
relationship between the execution time and the number of processors begins to deteriorate.
Table ix explains these results with a step by step breakdown of the execution times
reported for the sorting of integers on the T3D.
Step (1) clearly displays the ![]() complexity expected for radix sort, and it dominates the total execution
time for small values of p. The transpose operation in
Step (2) displays the
complexity expected for radix sort, and it dominates the total execution
time for small values of p. The transpose operation in
Step (2) displays the ![]() complexity we
originally suggested.
The dependence of
complexity we
originally suggested.
The dependence of ![]() on p simply becomes more pronounced as p increases and
on p simply becomes more pronounced as p increases and
![]() decreases. Step (3) exhibits the O(sp) complexity we anticipated,
since for
decreases. Step (3) exhibits the O(sp) complexity we anticipated,
since for ![]() , s is halved every other time p is
doubled. Steps (6) and (9) display the expected
, s is halved every other time p is
doubled. Steps (6) and (9) display the expected
![]() and
and ![]()
![]() for
for
![]() complexity,
respectively. Steps (7) and (8) exhibit the most complicated
behavior. The reason for this is that in Step (7), each processor must exchange
p subsequences with every other processor and must include with each subsequence a
record consisting of four integer values which will allow the unshuffling
in Step (8) to be performed efficiently. Hence, the
complexity,
respectively. Steps (7) and (8) exhibit the most complicated
behavior. The reason for this is that in Step (7), each processor must exchange
p subsequences with every other processor and must include with each subsequence a
record consisting of four integer values which will allow the unshuffling
in Step (8) to be performed efficiently. Hence, the
![]() transpose block size
in the case of 128
processors is nearly half that of the the case of 64 processors (1280 vs. 2816).
This, together with the fact that
transpose block size
in the case of 128
processors is nearly half that of the the case of 64 processors (1280 vs. 2816).
This, together with the fact that ![]() increases as a function of p, explains why
the time required for Step (7) actually increases for 128 processors.
Step (8) would also be expected to exhibit
increases as a function of p, explains why
the time required for Step (7) actually increases for 128 processors.
Step (8) would also be expected to exhibit
![]()
![]() for
for ![]() complexity.
But the scheme chosen for unshuffling also involves an O(p) amount
of overhead for each group of p subsequences to assess their relationship so that they can
be efficiently unshuffled. For sufficiently large values of p, this overhead
begins to dominate the complexity. While the data of Table ix
was collected for sorting integers on the T3D, the data from the SP-2-WN and
the T3D support the same analysis for sorting both integers and
doubles.
complexity.
But the scheme chosen for unshuffling also involves an O(p) amount
of overhead for each group of p subsequences to assess their relationship so that they can
be efficiently unshuffled. For sufficiently large values of p, this overhead
begins to dominate the complexity. While the data of Table ix
was collected for sorting integers on the T3D, the data from the SP-2-WN and
the T3D support the same analysis for sorting both integers and
doubles.
The graphs in Figure 2 examine the scalability of our regular sample sort
as a function of keys per processor ![]() , for differing numbers of processors.
They show that for a fixed number
of up to 64 processors there is an almost
linear dependence between the execution time and
, for differing numbers of processors.
They show that for a fixed number
of up to 64 processors there is an almost
linear dependence between the execution time and ![]() .
While this is certainly the expectation of our analytic
model for integers, it might at first appear to exceed our
prediction of a
.
While this is certainly the expectation of our analytic
model for integers, it might at first appear to exceed our
prediction of a ![]() computational complexity for
floating point values. However, this appearance of a linear
relationship is still quite reasonable when we consider that for the
range of values shown
computational complexity for
floating point values. However, this appearance of a linear
relationship is still quite reasonable when we consider that for the
range of values shown ![]() differs by only a factor of 1.2.
For p > 64, the relationship between the execution time and and
differs by only a factor of 1.2.
For p > 64, the relationship between the execution time and and ![]() is no longer linear. But based on our discussion of the data in Table ix,
for large p and relatively small n we would expect a sizeable contribution from those steps
which exhibit
is no longer linear. But based on our discussion of the data in Table ix,
for large p and relatively small n we would expect a sizeable contribution from those steps
which exhibit ![]() ,
, ![]() ,
and
,
and
![]() complexity,
which would explain this loss of linearity.
complexity,
which would explain this loss of linearity.
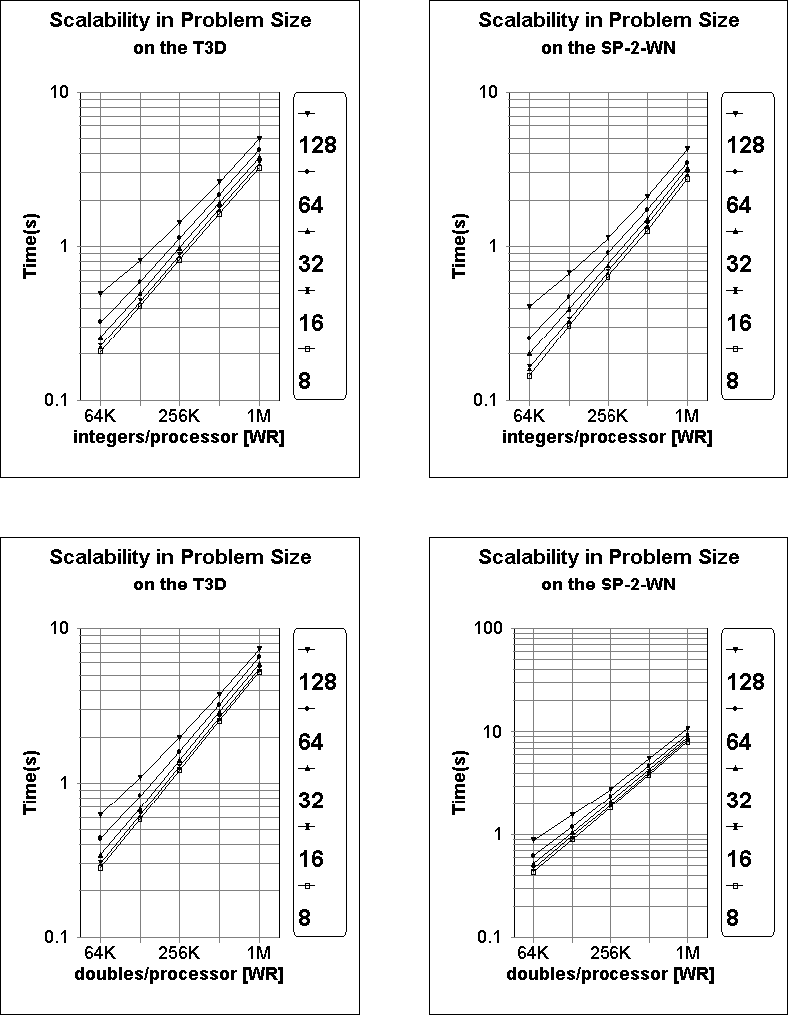
Figure 2: Scalability of sorting integers with respect to the number of
keys per processor ![]() , for differing numbers of processors.
, for differing numbers of processors.
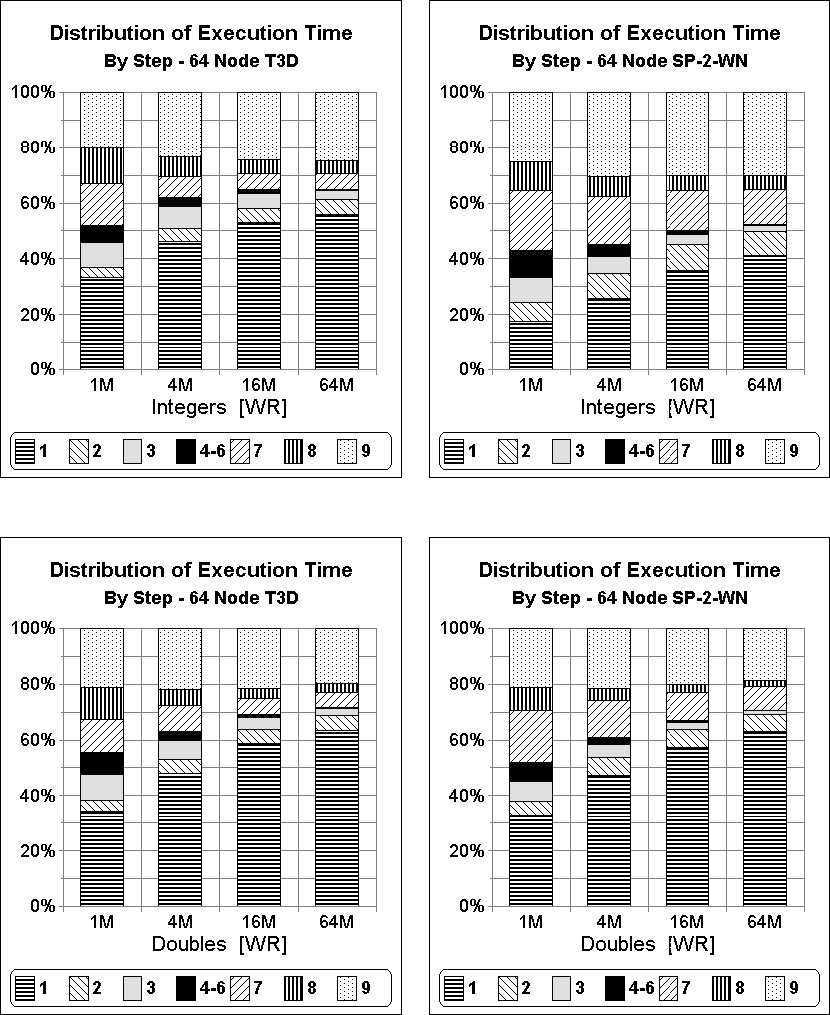
Figure 3: Distribution of execution time amongst the nine steps of
regular sample sort. Times are obtained for both a 64 node T3D and
a 64 node SP-2-WN using both the integer and the double versions
of the [WR] benchmark.
Finally, the graphs in Figure 3 examine the
relative costs of the nine steps in our regular sample sort algorithm.
Results are shown for both a 64 node T3D and a 64 node SP-2-WN,
using both the integer and the double versions of the [WR] benchmark.
Notice that for n = 64M integers, the sequential sorting,
unshuffling, and merging performed in Steps (1), (8),
and (9) consume approximately ![]() of the execution time on the T3D and approximately
of the execution time on the T3D and approximately ![]() of the execution
time on the SP-2. By contrast, the two transpose operations in
Steps (2) and (7) together consume only about
of the execution
time on the SP-2. By contrast, the two transpose operations in
Steps (2) and (7) together consume only about ![]() of the
execution time on the T3D and about
of the
execution time on the T3D and about ![]() of the execution time on the
SP-2. The difference in the distribution between these two platforms is
likely due in part to the fact that an integer is 64 bits on the T3D
while only
32 bits on the SP-2. By contrast, doubles are 64 bits on both platforms.
For n = 64M doubles, the sequential sorting, unshuffling, and merging
performed in Steps (3), (8), and (9) consume
approximately
of the execution time on the
SP-2. The difference in the distribution between these two platforms is
likely due in part to the fact that an integer is 64 bits on the T3D
while only
32 bits on the SP-2. By contrast, doubles are 64 bits on both platforms.
For n = 64M doubles, the sequential sorting, unshuffling, and merging
performed in Steps (3), (8), and (9) consume
approximately ![]() of the execution time on both platforms, whereas the two transpose
operations in Steps (2) and (7) together consume only about
of the execution time on both platforms, whereas the two transpose
operations in Steps (2) and (7) together consume only about
![]() of the execution time. Together, these results show that our
algorithm is extremely efficient in its communication performance.
of the execution time. Together, these results show that our
algorithm is extremely efficient in its communication performance.