Balancing load among processors is very important since poor balance of load generally causes poor processor utilization [19]. The load balancing problem is also important in developing fast solutions for basic combinatorial problems such as sorting, selection, list ranking, and graph problems [12,21].
This problem can be defined as follows.
The load in each processor 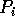 is given by an array
is given by an array 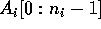 , where
, where
 represents the number of useful elements in
represents the number of useful elements in 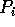 such that
such that
 and
and  .
We are supposed to redistribute the n
elements over the p processors such that
.
We are supposed to redistribute the n
elements over the p processors such that 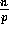 elements are stored
in each processor, where we have assumed without loss of generality that
p divides n.
elements are stored
in each processor, where we have assumed without loss of generality that
p divides n.
In this section, we develop
a simple and efficient load balancing algorithm for the BDM model.
The corresponding communication time is given by
 . The overall strategy is
described next.
. The overall strategy is
described next.
Let 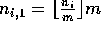 and
and  ,
for
,
for 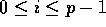 . Then, the overall strategy of the load balancing
algorithm can be described as follows: First, the load balancing problem of
the
. Then, the overall strategy of the load balancing
algorithm can be described as follows: First, the load balancing problem of
the  elements stored in the p arrays
elements stored in the p arrays
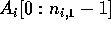 ,
,  , is considered and hence an
output array
, is considered and hence an
output array 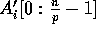 of
of 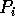 is generated.
The array
is generated.
The array  may have km or
may have km or 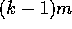 useful
elements, where
useful
elements, where 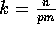 (steps 2 and 3).
Next, processors with
(steps 2 and 3).
Next, processors with 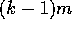 useful elements read m elements
from appropriate processors (Step 4). The details are given in the next
algorithm.
We assume for simplicity that all of n, p, and m are powers of two.
useful elements read m elements
from appropriate processors (Step 4). The details are given in the next
algorithm.
We assume for simplicity that all of n, p, and m are powers of two.
Algorithm Load_Balancing
Input : Each processor  contains an input array
contains an input array 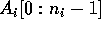 .
.
Output : The elements are redistributed in such a way that
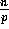 elements are stored in the output array
elements are stored in the output array
 of
of  , for
, for  .
.
begin
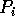 reads the p-1 values
reads the p-1 values  held in the remaining processors.
This step can be performed in
at most
held in the remaining processors.
This step can be performed in
at most 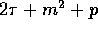 communication time by Lemma 3.2.
communication time by Lemma 3.2.
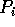 performs the following local computations:
performs the following local computations:
2.1 ¯ for ¯ j=0 to p-1 doRemark: The index t is chosen in such a way that, for i<t, processor{
;
;}
2.2 Compute the prefix sums
of
, and
compute
;
2.3 if
then
{ ¯
{
};
{
};
}
else
{
{
};
{
};
}
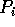 will read
will read 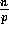 elements, and for
elements, and for 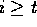 ,
, 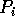 will read
will read 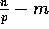 elements.
The indices
elements.
The indices 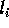 and
and 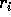 will be used in the next step
to determine the locations of the
will be used in the next step
to determine the locations of the 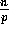 or
or  elements that will be moved to
elements that will be moved to 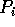 . Notice that this step takes
. Notice that this step takes
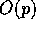 computation time.
computation time.
 reads
reads 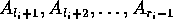 ,
and reads appropriate numbers of elements from
,
and reads appropriate numbers of elements from 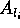 and
and 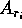 respectively.
respectively.
Remark:
This step needs a special attention since there are cases when
a set of consecutive processors read their elements from one processor,
say 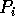 . Assume that h processors,
. Assume that h processors, 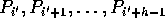 ,
have to read some appropriate elements from
,
have to read some appropriate elements from 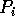 .
Notice that
.
Notice that 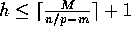 .
Then this step can be divided into two substeps as follows:
In the first substep, h-1 processors,
.
Then this step can be divided into two substeps as follows:
In the first substep, h-1 processors,
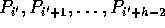 , read their elements from each such
, read their elements from each such
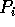 ; this substep can be done in
; this substep can be done in
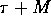 communication time by applying Corollary 3.1.
In the second substep, the rest of the routing is performed by using
a sequence of read prefetch operations since the remaining elements in each
processor are accessed only by a single processor.
Hence the total communication time required by this step is
communication time by applying Corollary 3.1.
In the second substep, the rest of the routing is performed by using
a sequence of read prefetch operations since the remaining elements in each
processor are accessed only by a single processor.
Hence the total communication time required by this step is
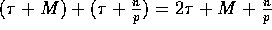 .
.
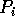 ,
,  , reads the remaining m
elements from the appropriate processors; the corresponding
indices
, reads the remaining m
elements from the appropriate processors; the corresponding
indices 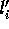 and
and 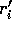 can be computed locally as in Step 2.
can be computed locally as in Step 2.
Remark:
This step can be completed in 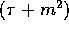 communication time
since each processor reads its m elements from
at most m processors, and these reads can be prefetched.
communication time
since each processor reads its m elements from
at most m processors, and these reads can be prefetched.
Thus, one can show the following theorem.
