Our computation model, the Block Distributed Memory (BDM), will be
defined in terms of four parameters p,  ,
, 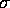 , and m.
As we will see later, the parameter
, and m.
As we will see later, the parameter  can be dropped without
loss of generality. The parameter p refers to the number of processors;
each such processor is viewed as a unit cost random access machine
(RAM). In addition, each processor has an interface unit to the
interconnection network that handles communication among the different
processors. Data are communicated between processors via point-to-point
messages; each message consists of a packet that holds
m words from consecutive locations of a local processor
memory. Since we are assuming the shared memory programming
model, each request to a remote location involves the preparation
of a request packet, the injection of the packet into the network,
the reception of the packet at the destination processor, and
finally the sending of a packet containing the contents of m
consecutive locations, including the requested value, back to the requesting
processor. We will model the cost of handling the request to
a remote location ( read or write) by the formula
can be dropped without
loss of generality. The parameter p refers to the number of processors;
each such processor is viewed as a unit cost random access machine
(RAM). In addition, each processor has an interface unit to the
interconnection network that handles communication among the different
processors. Data are communicated between processors via point-to-point
messages; each message consists of a packet that holds
m words from consecutive locations of a local processor
memory. Since we are assuming the shared memory programming
model, each request to a remote location involves the preparation
of a request packet, the injection of the packet into the network,
the reception of the packet at the destination processor, and
finally the sending of a packet containing the contents of m
consecutive locations, including the requested value, back to the requesting
processor. We will model the cost of handling the request to
a remote location ( read or write) by the formula  , where
, where  is
the maximum latency time it takes for a requesting processor
to receive the appropriate packet,
and
is
the maximum latency time it takes for a requesting processor
to receive the appropriate packet,
and  is the rate at which a processor can inject (receive) a word into
(from) the network.
Moreover, no processor can send or receive more
than one packet at a time.
As a result we note the following two observations. First, if
is the rate at which a processor can inject (receive) a word into
(from) the network.
Moreover, no processor can send or receive more
than one packet at a time.
As a result we note the following two observations. First, if
 is any permutation on p elements, then a remote memory
request issued by processor
is any permutation on p elements, then a remote memory
request issued by processor  and destined for processor
and destined for processor
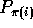 can be completed in
can be completed in 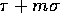 time for
all processors
time for
all processors 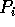 ,
,  , simultaneously. Second, k remote access requests
issued by k distinct processors and destined to the same
processor will require
, simultaneously. Second, k remote access requests
issued by k distinct processors and destined to the same
processor will require  time to be completed; in
addition, we do not make any assumption on the relative order
in which these requests will be completed.
time to be completed; in
addition, we do not make any assumption on the relative order
in which these requests will be completed.
Most current interconnection networks
for multiprocessors use several hardware and software techniques
for hiding memory latency. In our model, we allow pipelined prefetching
for hiding memory latency.
In particular, k
prefetch read operations issued by
a processor can be completed in  time.
time.
The underlying communication model for BDM is
consistent with the LogP and the postal models
[8,13,5] but with the
addition of the parameter m that incorporates spatial
locality. However, our model does not allow low-level handling
of message passing primitives except implicitly through data accesses.
In particular, an algorithm written in our model can specify
the initial data placement among the local memories of the
p processors, can use the processor id to refer to specific data
items, and can use synchronization barriers to
synchronize the activities of various processors
whenever necessary. Remote data accesses are charged
according to the communication model specified above. As
for synchronization barriers, we make the assumption that,
on the BDM model, they
are provided as primitive operations. There are
two main reasons for making this assumption. The first is
that barriers can be implemented in hardware efficiently at a relatively
small cost. The second is that we
can make the latency parameter  large enough to account
for synchronization costs. The resulting communication costs
will be on the conservative side but that should not affect
the overall structure of the resulting algorithms.
large enough to account
for synchronization costs. The resulting communication costs
will be on the conservative side but that should not affect
the overall structure of the resulting algorithms.
The complexity of a parallel algorithm on the BDM model will
be evaluated in terms of two measures: the computation time
 , and the communication time
, and the communication time 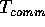 . The measure
. The measure
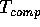 refers to the maximum of the local computation performed
on any processor as measured on the standard sequential
RAM model. The
communication time
refers to the maximum of the local computation performed
on any processor as measured on the standard sequential
RAM model. The
communication time 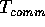 refers to the total amount of
communication time spent by the overall algorithm in accessing
remote data. Our main goal is the design of parallel algorithms
that achieve optimal or near-optimal computational speedups, that is,
refers to the total amount of
communication time spent by the overall algorithm in accessing
remote data. Our main goal is the design of parallel algorithms
that achieve optimal or near-optimal computational speedups, that is,
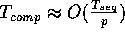 , where
, where 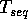 is the sequential complexity of the
problem under consideration, in such a way that the total
communication time
is the sequential complexity of the
problem under consideration, in such a way that the total
communication time 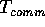 is minimized.
is minimized.
Since 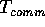 is treated separately from
is treated separately from  , we
can normalize this measure by dividing it by
, we
can normalize this measure by dividing it by  .
The underlying
communication model for BDM can now be viewed as the postal
model [5] but with the added parameter m reflecting spatial locality.
Hence an access operation to a remote location takes
.
The underlying
communication model for BDM can now be viewed as the postal
model [5] but with the added parameter m reflecting spatial locality.
Hence an access operation to a remote location takes  time,
and k prefetch read operations can be executed in
time,
and k prefetch read operations can be executed in 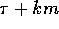 time. Note
that the parameter
time. Note
that the parameter  should now be viewed as an upper bound on
the capacity of the interconnection network, i.e., an upper bound
on the maximum number of words in transit from or to a processor. In our
estimates of the bounds on the communication time, we make the
simplifying (and reasonable) assumption that
should now be viewed as an upper bound on
the capacity of the interconnection network, i.e., an upper bound
on the maximum number of words in transit from or to a processor. In our
estimates of the bounds on the communication time, we make the
simplifying (and reasonable) assumption that  is an integral
multiple of m.
is an integral
multiple of m.
We believe that locality is an important factor that has
to be taken into consideration when designing parallel algorithms
for large scale multiprocessors. We have incorporated the
parameter m into our model to emphasize the importance of
spatial locality. The notion of
processor locality also seems to be important in
current multiprocessor architectures; these architectures
tend to be hierarchical,
and hence the latency  is much higher for accessing processors
that are further up in the hierarchy than those that are
``close by''. This feature can be incorporated into our model
by modifying the value of
is much higher for accessing processors
that are further up in the hierarchy than those that are
``close by''. This feature can be incorporated into our model
by modifying the value of  to reflect the cost associated
with the level of hierarchy that needs to be used for a remote
memory access. This can be done in a similar fashion as in
the memory hierarchy model studied in [2] for
sequential processors. However in this paper we have opted
for simplicity and decided not to include the processor locality
into consideration.
to reflect the cost associated
with the level of hierarchy that needs to be used for a remote
memory access. This can be done in a similar fashion as in
the memory hierarchy model studied in [2] for
sequential processors. However in this paper we have opted
for simplicity and decided not to include the processor locality
into consideration.
Several models that have been discussed in the literature, other than the LogP and the postal models referred to earlier, are related to our BDM model. However there are significant differences between our model and each of these models. For example, both the Asynchronous PRAM [9] and the Block PRAM [1] assume the presence of a shared memory where intermediate results can be held; in particular, they both assume that the data is initially stored in this shared memory. This makes data movement operations considerably simpler than in our model. Another example is the Direct Connection Machine (DCM) with latency [14] that uses message passing primitives; in particular, this model does not allow pipelined prefetching as we do in the BDM model.