We use the Block Distributed Memory (BDM) Model ([21], [22]) as a computation model for developing and analyzing our parallel algorithms on distributed memory machines. This model allows the design of algorithms using a single address space and does not assume any particular interconnection topology. The model captures performance by incorporating a cost measure for interprocessor communication induced by remote memory accesses. The cost measure includes parameters reflecting memory latency, communication bandwidth, and spatial locality. This model allows the initial placement of data and prefetching.
The complexity of parallel algorithms will be evaluated in terms of
two measures: the computation time 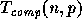 , and the communication time
, and the communication time
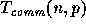 . The measure
. The measure 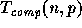 refers to the maximum of the local
computations performed on any processor as measured on the standard
sequential RAM model. The communication time
refers to the maximum of the local
computations performed on any processor as measured on the standard
sequential RAM model. The communication time 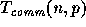 refers to the
total amount of communications time spent by the overall algorithm in
accessing remote data. Using the BDM model, an access operation to a
remote location takes
refers to the
total amount of communications time spent by the overall algorithm in
accessing remote data. Using the BDM model, an access operation to a
remote location takes 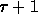 time, and l prefetch read
operations can be executed in
time, and l prefetch read
operations can be executed in 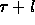 time, where
time, where  is the
normalized maximum latency of any message sent in the communications
network. No processor can send or receive more than one word at a
time.
is the
normalized maximum latency of any message sent in the communications
network. No processor can send or receive more than one word at a
time.
Two useful data movement patterns, matrix transposition and broadcasting, are discussed next, and their analyses will be included as primitives in the algorithms that follow.
Given a 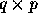 matrix on a p processor machine, where p
divides q, the matrix transposition consists of rearranging the data
such that the first
matrix on a p processor machine, where p
divides q, the matrix transposition consists of rearranging the data
such that the first 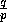 rows of elements are destined to the
first processor, the second
rows of elements are destined to the
first processor, the second 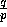 rows to the second
processor, and so on, with the last
rows to the second
processor, and so on, with the last 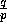 rows of the matrix
destined to the last processor. An efficient matrix transposition
algorithm consists of p iterations such that, during iteration i,
each processor
rows of the matrix
destined to the last processor. An efficient matrix transposition
algorithm consists of p iterations such that, during iteration i,
each processor  prefetches the appropriate block of
prefetches the appropriate block of
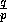 elements from processor
elements from processor 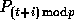 .
.
Next, an efficient BDM algorithm is given which takes q elements on a single processor and broadcasts them to the other p-1 processors using just two matrix transpositions.
Performance analysis given will reflect the execution times from
implementations on the CM-5, SP-2, and CS-2, each with p = 32
parallel processing nodes. The algorithms are written in SPLIT-C , a
parallel extension of the C programming language, primarily intended
for distributed memory multiprocessors. SPLIT-C can express the
capabilities of the BMD model and provides a shared global address
space, constructs to express data layout, and split-phase
assignments. The split-phase assignment operator, 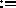 ,
prefetches data from the specified remote location into local memory.
Computation can be overlapped with the remote request, and the
sync() function allows each processor to stall until all data
prefetching is complete. The SPLIT-C language also supplies a
barrier() function for the global synchronization of the processors.
,
prefetches data from the specified remote location into local memory.
Computation can be overlapped with the remote request, and the
sync() function allows each processor to stall until all data
prefetching is complete. The SPLIT-C language also supplies a
barrier() function for the global synchronization of the processors.